Yuting Zhang1, Yijie Guo1, Yixin Jin1, Yijun Luo1, Zhiyuan He1, Honglak Lee1,2
1 University of Michigan, Ann Arbor; 2 Google Brain
Deep neural networks can model images with rich latent representations, but they cannot naturally conceptualize structures of object categories in a human-perceptible way. This paper addresses the problem of learning object structures in an image modeling process without supervision. We propose an autoencoding formulation to discover landmarks as explicit structural representations. The encoding module outputs landmark coordinates, whose validity is ensured by constraints that reflect the necessary properties for landmarks. The decoding module takes the landmarks as a part of the learnable input representations in an end-to-end differentiable framework. Our discovered landmarks are semantically meaningful and more predictive of manually annotated landmarks than those discovered by previous methods. The coordinates of our landmarks are also complementary features to pre-trained deep-neural-network representations in recognizing visual attributes. In addition, the proposed method naturally creates an unsupervised, perceptible interface to manipulate object shapes and decode images with controllable structures.
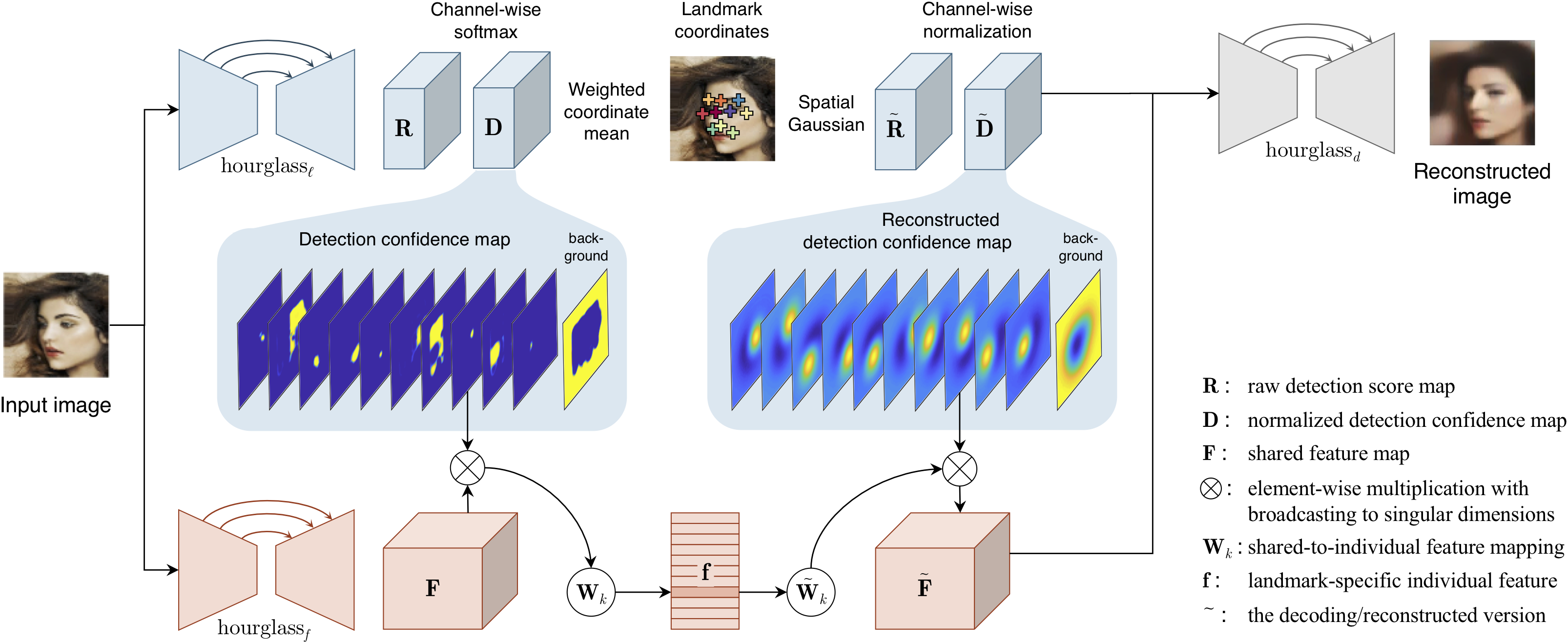
Overall of the neural network architecture.
Paper
Unsupervised Discovery of Object Landmarks as Structural Representations
Yuting Zhang, Yijie Guo, Yixin Jin, Yijun Luo, Zhiyuan He, Honglak Lee
Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
Oral presentation
[]
[]
[paper (main, appendices, supp-videos .tar.gz)]
[arXiv]
[project (code & results)]
[poster]
[slides]
[oral presentation .mp4]
@inproceedings{2018-cvpr-lmdis-rep,
author={Yuting Zhang and Yijie Guo and Yixin Jin and Yijun Luo and Zhiyuan He and Honglak Lee},
booktitle={Conference on Computer Vision and Pattern Recognition ({CVPR})},
title={Unsupervised Discovery of Object Landmarks as Structural Representations},
year={2018},
month={June},
url={http://www.ytzhang.net/files/publications/2018-cvpr-lmdis-rep.pdf},
arxiv={1804.04412}
}
Code
We provide code and model release in Python+TensorFlow. The code can be obtained from our GitHub repository:
- Code & Models (@GitHub): https://github.com/YutingZhang/lmdis-rep
Overview of Results
1. Facial landmark discovery & its application to supervised tasks


| Method | Test set error | ||
| MAFL | ALFW | ||
| Fully supervised |
RCPR X. P. Burgos-Artizzu, P. Perona, and P. Dollár. Robust face landmark estimation under occlusion. In ICCV, 2013. |
- | 11.60 |
CFAN Jie Zhang, Shiguang Shan, Meina Kan, and Xilin Chen. Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment. In ECCV, 2014. |
15.84 | 10.94 | |
TCDCN Zhanpeng Zhang, Ping Luo, Chen Change Loy, and Xiaoou Tang. Learning deep representation for face alignment with auxiliary attributes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(5):918–930, 2016. |
7.95 | 7.65 | |
Cascaded CNN Yi Sun, Xiaogang Wang, and Xiaoou Tang. Deep convolutional network cascade for facial point detection. In CVPR, 2013. |
9.73 | 8.97 | |
RAR Shengtao Xiao, Jiashi Feng, Junliang Xing, Hanjiang Lai, Shuicheng Yan, and Ashraf Kassim. Robust facial landmark detection via recurrent attentive-refinement networks. In ECCV, 2016. |
- | 7.23 | |
MTCNN Zhanpeng Zhang, Ping Luo, Chen Change Loy, and Xiaoou Tang. Facial landmark detection by deep multi-task learning. In ECCV, 2014. |
5.39 | 6.90 | |
| Unsupervised discovery |
Thewlis et al. (50 discovered landmarks) James Thewlis, Hakan Bilen, and Andrea Vedaldi. Unsupervised learning of object landmarks by factorized spatial embeddings. In ICCV, 2017. |
6.67 | 10.53 |
Thewlis et al. (dense object frames) James Thewlis, Hakan Bilen, and Andrea Vedaldi. Unsupervised learning of object frames by dense equivariant image labelling. In NIPS, 2017. |
5.83 | 8.80 | |
Ours (10 discovered landmarks) This is our method. |
3.46 | 7.01 | |
Ours (30 discovered landmarks) This is our method. |
3.15 | 6.58 | |
| Hover over (or click) the name of a method to see the citation. | |||

| Method | Ours (discovered landmarks) | FaceNet (top-layer) | FaceNet (conv-layer) |
| Feature dimension | 60 | 128 | 1792 |
| Accuracy / % | 83.2 | 80.0 | 82.4 |
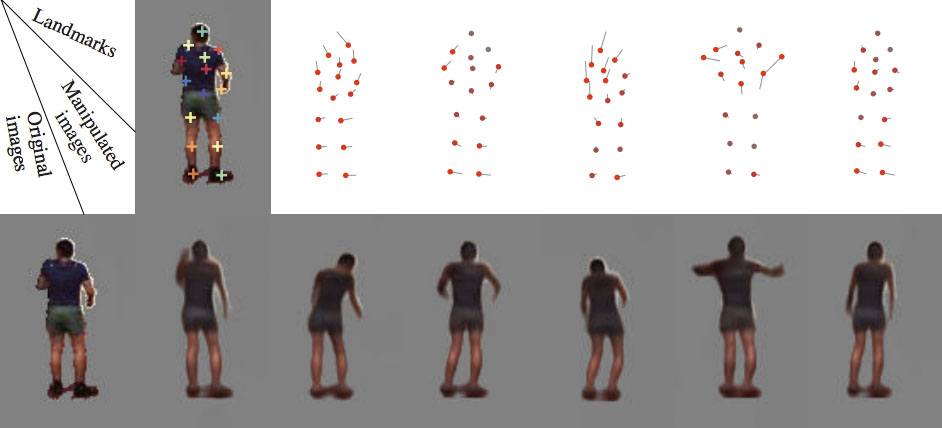
2. Image manipulation using discovered landmarks
3. Landmark discovery on cat heads, cars, shoes, and human bodies




